1. 어텐션 메커니즘
기존의 RNN(Recurrent Neural Network)이나 LSTM(Long Short-Term Memory) 모델은 입력 데이터를 순차적으로 처리하기 때문에 긴 문장에서 중요한 정보를 잃어버리거나, 멀리 떨어진 단어 간의 관계를 잘 파악하지 못하는 문제가 있었습니다. 어텐션은 입력 문장의 모든 단어를 한 번에 보고, 어떤 단어가 중요한지 가중치를 계산하여 집중하는 방법입니다.
예를 들어, "나는 오늘 학교에서 수학 시험을 봤다."라는 문장에서 "시험"이라는 단어가 가장 중요한 의미를 가진다고 가정합시다. 어텐션은 이 문장을 처리할 때 "시험"에 더 높은 가중치를 주고, 덜 중요한 단어에는 낮은 가중치를 주는 방식으로 학습합니다.
2. 단어 임베딩과 문맥
단어의 의미는 그 단어가 어떤 문맥에서 쓰이느냐에 따라 달라집니다. 예를 들어 “귤 과 사과”에서는 ‘사과’가 과일 의미로 쓰이고, “어제일 을 사과”에서는 사죄 의미로 쓰입니다. 단어 임베딩 학습에서는 이런 문맥적 공동출현 정보를 가중치로 반영하여, 벡터 공간에서 단어들을 서로 끌어당기거나 밀어내며 위치를 조정합니다. 그 결과 ‘사과’ 벡터는 과일과 사죄라는 두 의미의 문맥 사이 어딘가에 자리 잡게 되고, 이것이 바로 단어 임베딩이 단어 간 의미 관계를 학습하는 방식입니다.
아래 그림은 단어 임베딩이 문맥을 통해 단어 사이의 관계를 어떻게 학습하는지를 보여줍니다. 왼쪽 표는 문장에서 단어들이 함께 등장할 때 생기는 공동출현 가중치(W1)를 나타내며, 예를 들어 “귤 과 사과”라는 문맥에서는 사과가 과일 쪽으로, “어제일 을 사과”라는 문맥에서는 사과가 행위·사죄 쪽으로 끌리게 됩니다. 오른쪽 그림은 이러한 가중치가 반영되어 학습 과정에서 단어 벡터가 조금씩 이동하는 과정을 시각화한 것으로, 결국 사과는 과일 의미와 사죄 의미 사이의 중간 어딘가에 위치하게 됩니다. 즉, 단어의 의미는 문맥 속에서 결정되며, 임베딩 학습은 자주 함께 등장하는 단어끼리 가까워지도록 단어 벡터 공간을 정렬하는 과정입니다.

3. 토큰화와 패딩
자연어 처리에서 문장을 다루기 위해서는 먼저 문장을 단어 단위로 나누는 토큰화(tokenization) 과정이 필요합니다. 예를 들어 “커피 한잔 어때?”라는 문장은 [커피, 한잔, 어때]로 나눠지고, 각 단어는 임베딩을 통해 고정된 길이의 숫자 벡터(예: 512차원)로 표현됩니다. 하지만 문장의 길이는 제각각이기 때문에, 모델에 넣기 위해서는 모든 문장을 같은 길이로 맞춰야 합니다. 이때 짧은 문장은 패딩(padding) 을 이용해 빈칸을 채워 줍니다. 즉, “커피→T1, 한잔→T2, 어때→T3”와 같은 실제 단어 벡터 뒤에 패딩 토큰(PD)을 추가하여 입력을 일정하게 만들면, 모델은 문장의 의미를 잃지 않으면서도 효율적으로 학습할 수 있습니다. 예를 들어, “오늘 날씨 어때?”라는 문장은 [오늘, 날씨, 어때, PD], “커피 한잔 어때?”는 [커피, 한잔, 어때, PD]처럼 동일한 길이로 변환됩니다. 이렇게 토큰화와 패딩은 텍스트 데이터를 딥러닝 모델이 다룰 수 있는 숫자 행렬로 바꾸는 가장 기본적이면서도 중요한 과정입니다.

4. 멀티-헤드 어텐션
트랜스포머 모델에서 단어 하나는 보통 512차원의 임베딩 벡터로 표현되는데, 이 벡터 전체를 한 번에 다루는 대신 8개의 64차원 벡터로 분할하여 각각을 다른 ‘시선(head)’으로 처리합니다. 이렇게 하면 모델은 같은 문맥 속 단어라도 의미의 다양한 측면—예를 들어 ‘커피’라는 단어가 음료로 쓰였는지, 일상 대화 속 제안으로 쓰였는지—를 동시에 포착할 수 있습니다. 즉, 하나의 임베딩을 여러 개의 작은 벡터(헤드)로 나눠 병렬적으로 어텐션을 수행함으로써, 문맥을 더 풍부하게 이해하고 단어 간 복잡한 관계를 학습할 수 있게 되는 것입니다.

예를 들어, 문장 “커피 한잔 어때?”에서 ‘커피’라는 단어 벡터(512차원)는 8개의 헤드로 분리됩니다. 어떤 헤드는 ‘커피–음료’ 관계에 집중하고, 다른 헤드는 ‘커피–제안 표현(어때)’ 관계를 본다거나, 또 다른 헤드는 ‘커피–숫자 표현(한잔)’ 관계를 본다고 할 수 있습니다. 이렇게 다양한 관점을 합쳐 최종적으로 더 풍부한 표현이 만들어지는 것이 멀티-헤드 어텐션의 장점입니다.
5. 셀프 어텐션
셀프 어텐션(Self-Attention)에서는 입력 임베딩을 이용해 단어들 사이의 관계를 수치적으로 계산합니다. 먼저 각 단어의 임베딩 벡터를 복사하여 두 개의 행렬을 만들고, 하나는 그대로 두고 다른 하나는 전치(transpose)하여 행과 열을 바꿉니다. 이렇게 준비된 두 행렬을 곱하면 각 단어가 다른 단어와 얼마나 관련이 있는지를 나타내는 유사도 행렬이 만들어집니다. 예를 들어 “귤, 과, 사과”라는 문장에서 ‘사과’ 벡터와 ‘귤’ 벡터의 내적을 통해 두 단어의 관련성을 계산하고, 이를 W1 같은 값으로 저장합니다. 이 행렬은 결국 모델이 어떤 단어를 더 주목해야 할지를 결정하는 근거가 됩니다. 즉, 셀프 어텐션은 행렬 곱 연산을 통해 모든 단어 쌍의 관계를 한 번에 계산하고, 이를 토대로 문맥을 더 깊이 이해하게 만드는 핵심 메커니즘입니다.
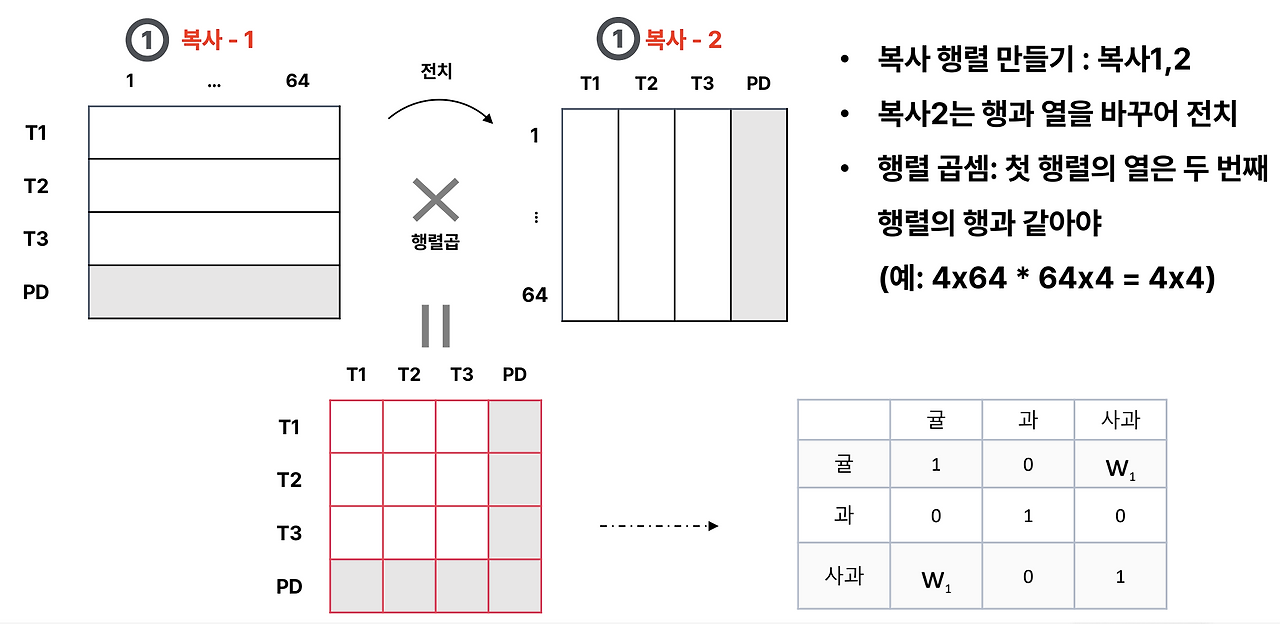
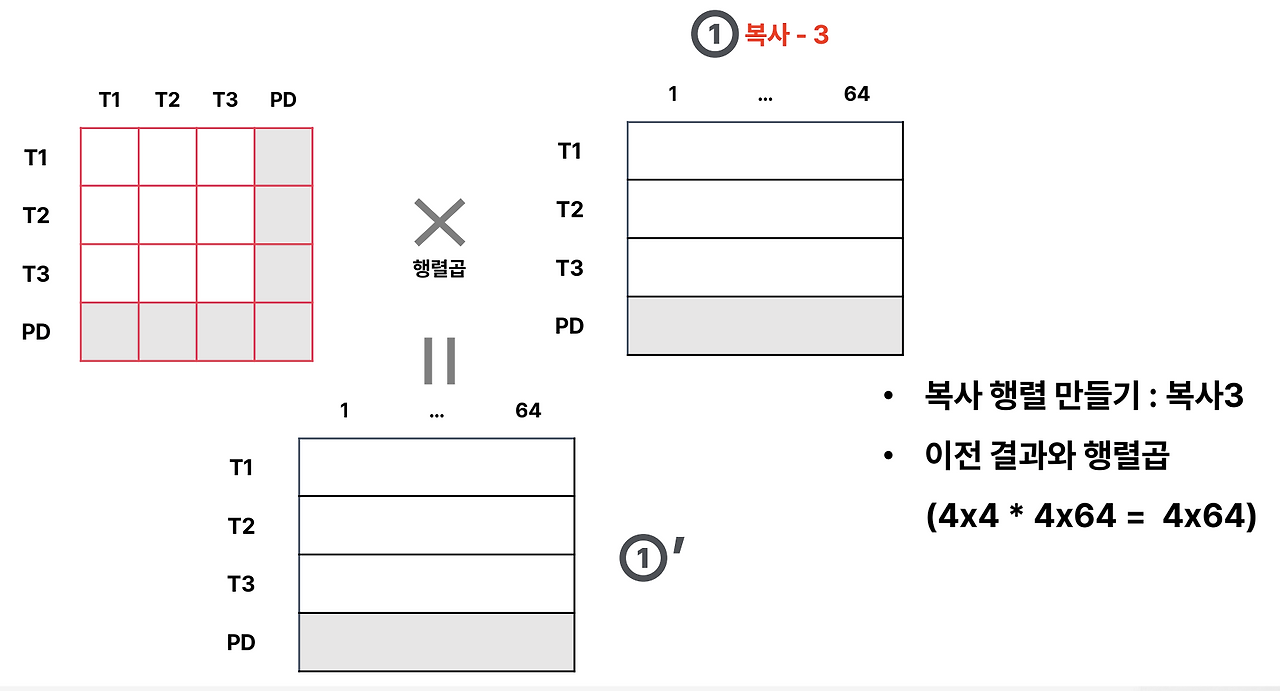
이전 단계에서 얻은 유사도 행렬(4×4)이 준비되고, 여기에 각 단어의 64차원 임베딩을 담은 Value 행렬(4×64)을 곱해 줍니다. 그 결과는 (4×64) 형태의 새로운 표현으로, 각 단어가 다른 단어들과의 관계를 고려해 업데이트된 벡터가 됩니다. 예를 들어 “커피 한잔 어때?”라는 문장에서 ‘커피’라는 단어 벡터는 단순히 자기 자신만을 표현하는 것이 아니라, “한잔”이나 “어때” 같은 단어와의 관련성 가중치를 곱해 더해진 최종 벡터로 변환됩니다. 이렇게 해서 모델은 문맥 속에서 각 단어의 의미를 풍부하게 반영할 수 있으며, 이것이 트랜스포머가 단어 간 관계를 이해하는 중요한 방식입니다.
6. 헤드 결합으로 완성되는 표현
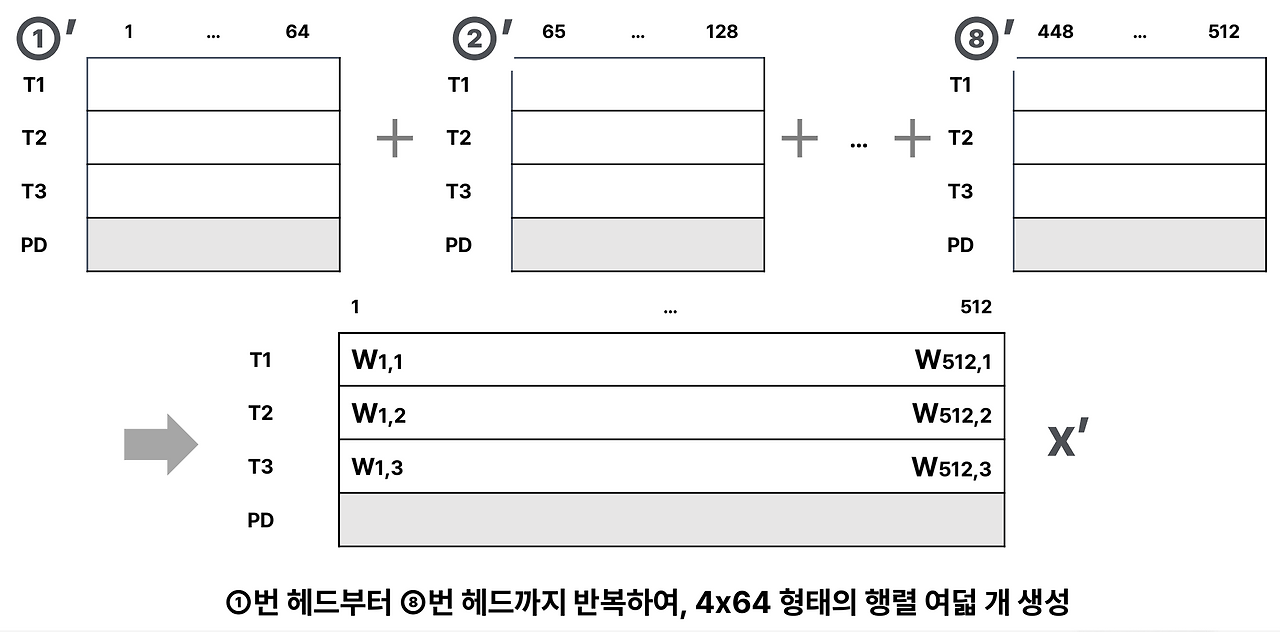
멀티-헤드 어텐션에서는 하나의 512차원 임베딩 벡터를 8개의 64차원 벡터로 나눠 각각 독립적으로 어텐션을 계산합니다. 이렇게 얻은 여러 개의 결과 행렬(예: 4×64)을 다시 이어 붙여(concatenate) 원래 차원인 512차원의 행렬로 복원하는데, 이 과정을 거쳐 최종 출력 X′가 만들어집니다. 즉, 각 헤드는 같은 단어라도 서로 다른 문맥적 특징을 학습하며, 마지막에 이 다양한 시선들을 합쳐 더 풍부한 의미 표현을 형성하는 것입니다. 예를 들어 “커피 한잔 어때?”라는 문장에서 어떤 헤드는 “커피–음료” 관계를, 다른 헤드는 “한잔–수량 표현”을, 또 다른 헤드는 “어때–제안” 의미를 포착한 뒤, 이 결과들을 모아 하나의 통합된 표현으로 완성하는 방식입니다.
7. 쿼리(Query), 키(Key), 값(Value)
Self-Attention은 입력 임베딩에서 쿼리(Query), 키(Key), 밸류(Value)라는 세 가지 행렬을 복사해 만들어냅니다. 쿼리는 질문을 던지는 역할, 키는 단서를 제공하는 역할, 밸류는 실제 답변 역할을 한다고 이해할 수 있습니다. 예를 들어 한 문장의 각 단어 벡터(4×64)를 기준으로 쿼리와 키의 내적을 계산하면 단어 간 연관성을 나타내는 4×4 유사도 행렬이 생성되고, 이 값으로 밸류 행렬을 가중합하여 최종 출력(4×64)이 만들어집니다. 즉, “커피 한잔 어때?”라는 문장에서 ‘커피’라는 단어는 쿼리로서 다른 단어들을 바라보고, 키를 통해 어떤 단어가 중요한지를 판단하며, 그 결과 밸류가 조정되어 문맥에 맞는 새로운 ‘커피’ 표현이 완성되는 것입니다. 이처럼 쿼리·키·밸류는 Self-Attention이 단어 간 관계를 정교하게 계산하고 문맥 이해를 가능하게 하는 핵심 요소입니다.

8. 어텐션 스코어
Self-Attention에서는 쿼리(Query)와 키(Key)의 내적을 통해 단어 간 유사도를 계산하지만, 값이 너무 커질 경우 학습이 불안정해지므로 이를 헤드 차원의 제곱근으로 나누어 스케일링합니다. 이후 스케일링된 값은 소프트맥스(softmax) 함수를 거쳐 0과 1 사이의 확률 값으로 변환되고, 각 행의 합이 1이 되도록 정규화됩니다. 이렇게 하면 모델은 어떤 단어에 더 집중할지 비율을 정할 수 있습니다. 또한 문장의 길이를 맞추기 위해 추가된 패딩 토큰은 소프트맥스 전에 를 더해 결과적으로 가중치가 0이 되도록 처리합니다.

9. 문장 길이와 배치 처리
트랜스포머 모델에서 문장을 어텐션에 입력하려면 일정한 형식으로 변환해야 합니다. 먼저 문장의 시작과 끝을 알리기 위해 <sos>(start of sentence), <eos>(end of sentence) 토큰을 붙이고, 문장의 길이를 맞추기 위해 짧은 문장은 패딩(PD) 토큰으로 채웁니다. 이렇게 하면 “커피 한잔 어때” 같은 짧은 문장과 “오늘 날씨 좋네”, “옷이 어울려요”처럼 길이가 다른 문장도 동일한 길이의 행렬로 변환할 수 있습니다. 또 한 번에 여러 개의 문장을 처리하기 위해 배치(batch) 단위로 묶어 입력하면, 모델은 병렬 연산을 통해 더 빠르고 효율적으로 학습할 수 있습니다. 즉, 문장 길이를 맞추고 배치 크기를 설정하는 과정은 어텐션이 문맥을 올바르게 이해하고 GPU 연산 효율을 극대화하기 위한 핵심 전처리 단계입니다.

import numpy as np
# 전체 출력 형식을 소수점 이하 네 자리로 설정
np.set_printoptions(precision=4, suppress=True)
# 단어와 해당 임베딩 벡터를 딕셔너리로 정의합니다.
embedding_dict = {
'<sos>': np.random.rand(512),
'<eos>': np.random.rand(512),
'커피': np.random.rand(512),
'한잔': np.random.rand(512),
'어때': np.random.rand(512),
'오늘': np.random.rand(512),
'날씨': np.random.rand(512),
'좋네': np.random.rand(512),
'옷이': np.random.rand(512),
'어울려요': np.random.rand(512),
'PAD': np.zeros(512) # 패딩 벡터는 0으로 채웁니다.
}
# 입력 문장
sentences = [
['<sos>', '커피', '한잔', '어때', '<eos>'],
['<sos>', '오늘', '날씨', '좋네', '<eos>'],
['<sos>', '옷이', '어울려요', '<eos>', 'PAD']
]
# 토큰을 임베딩 벡터로 변환
embeddings = np.array([[embedding_dict[token] for token in sentence] for sentence in sentences])
print("임베딩 행렬의 형태:", embeddings.shape)
# 쿼리, 키, 밸류 행렬 초기화
num_heads = 8
head_dim = 512 // num_heads # 각 헤드의 차원
heads = np.split(embeddings, num_heads, axis=2) # 512차원 임베딩 벡터를 8개의 헤드로 분할하여 heads에 저장
queries = heads.copy()
keys = [head.transpose(0, 2, 1) for head in heads] # 키 행렬을 각 헤드의 전치를 통해 초기화 (첫 번째 축: 배치 크기, 두 번째 축: 문장 길이, 세 번째 축: 헤드 차원)
values = heads.copy()
print("쿼리 행렬의 형태:", queries[0].shape)
print("키 행렬의 형태:", keys[0].shape)
print("밸류 행렬의 형태:", values[0].shape)
# 특정 토큰 (커피, 한잔, 어때)의 인덱스
tokens_of_interest = ['커피', '한잔', '어때']
indices_of_interest = [sentences[0].index(token) for token in tokens_of_interest]
# 어텐션 이전의 임베딩 테이블 중 특정 토큰들의 평균 값 계산
print("어텐션 이전의 임베딩 테이블 중 '커피', '한잔', '어때' 토큰의 평균 값:")
initial_avg = np.mean(embeddings[0, indices_of_interest, :], axis=1)
print(initial_avg)
# 스케일링 및 어텐션 스코어 계산
attention_scores = np.matmul(queries[0], keys[0])
scaling_factor = np.sqrt(head_dim)
scaled_attention_scores = attention_scores / scaling_factor
# 패딩 처리
mask = np.array([[token == 'PAD' for token in sentence] for sentence in sentences])
mask = mask[:, np.newaxis, :] # 차원을 맞추기 위해 확장
scaled_attention_scores = np.where(mask, -np.inf, scaled_attention_scores)
# 소프트맥스 적용 함수
def softmax(x):
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
# 복원된 헤드를 저장할 리스트
restored_heads = []
for i in range(num_heads):
query = queries[i]
key = keys[i]
value = values[i]
# 내적 계산 후 스케일링
attention_scores = np.matmul(query, key) / scaling_factor
# 패딩 처리
mask = np.array([[token == 'PAD' for token in sentence] for sentence in sentences])
mask = mask[:, np.newaxis, :] # 차원을 맞추기 위해 확장
attention_scores = np.where(mask, -np.inf, attention_scores)
# 소프트맥스 적용
attention_weights = softmax(attention_scores)
# 밸류와의 곱셈
restored_head = np.matmul(attention_weights, value)
restored_heads.append(restored_head)
# 모든 헤드를 결합하여 원래 차원으로 복원
final_output = np.concatenate(restored_heads, axis=2)
# 어텐션 이후의 결과 중 특정 토큰들의 평균 값 계산
print("어텐션 이후의 결과 중 '커피', '한잔', '어때' 토큰의 평균 값:")
final_avg = np.mean(final_output[0, indices_of_interest, :], axis=1)
print(final_avg)
import numpy as np
# 전체 출력 형식을 소수점 이하 네 자리로 설정
np.set_printoptions(precision=4, suppress=True)
# 단어와 해당 임베딩 벡터를 딕셔너리로 정의합니다.
embedding_dict = {
'<sos>': np.random.rand(512),
'<eos>': np.random.rand(512),
'커피': np.random.rand(512),
'한잔': np.random.rand(512),
'어때': np.random.rand(512),
'오늘': np.random.rand(512),
'날씨': np.random.rand(512),
'좋네': np.random.rand(512),
'옷이': np.random.rand(512),
'어울려요': np.random.rand(512),
'PAD': np.zeros(512) # 패딩 벡터는 0으로 채웁니다.
}
# 입력 문장
sentences = [
['<sos>', '커피', '한잔', '어때', '<eos>'],
['<sos>', '오늘', '날씨', '좋네', '<eos>'],
['<sos>', '옷이', '어울려요', '<eos>', 'PAD']
]
max_len = 6 # 최대 문장 길이
# 토큰을 임베딩 벡터로 변환
embeddings = np.array([[embedding_dict[token] for token in sentence] for sentence in sentences])
print("임베딩 행렬의 형태:", embeddings.shape) # (3, 6, 512)
# 쿼리, 키, 밸류 행렬 초기화
num_heads = 8
head_dim = 512 // num_heads # 각 헤드의 차원
heads = np.split(embeddings, num_heads, axis=2) # 512차원 임베딩 벡터를 8개의 헤드로 분할하여 heads에 저장
queries = heads.copy()
keys = [head.transpose(0, 2, 1) for head in heads] # 키 행렬을 각 헤드의 전치를 통해 초기화 (첫 번째 축: 배치 크기, 두 번째 축: 문장 길이, 세 번째 축: 헤드 차원)
values = heads.copy()
print("쿼리 행렬의 형태:", queries[0].shape) # (3, 6, 64)
print("키 행렬의 형태:", keys[0].shape) # (3, 64, 6)
print("밸류 행렬의 형태:", values[0].shape) # (3, 6, 64)
# 특정 토큰 (커피, 한잔, 어때)의 인덱스
tokens_of_interest = ['커피', '한잔', '어때']
indices_of_interest = [sentences[0].index(token) for token in tokens_of_interest]
# 어텐션 이전의 임베딩 테이블 중 특정 토큰들의 평균 값 계산
print("어텐션 이전의 임베딩 테이블 중 '커피', '한잔', '어때' 토큰의 평균 값:")
initial_avg = np.mean(embeddings[0, indices_of_interest, :], axis=1)
print(initial_avg)
# 스케일링 및 어텐션 스코어 계산
attention_scores = np.matmul(queries[0], keys[0])
scaling_factor = np.sqrt(head_dim)
scaled_attention_scores = attention_scores / scaling_factor
# 패딩 처리
mask = np.array([[token == 'PAD' for token in sentence] for sentence in sentences])
mask = mask[:, np.newaxis, :] # 차원을 맞추기 위해 확장
scaled_attention_scores = np.where(mask, -np.inf, scaled_attention_scores)
# 소프트맥스 적용 함수
def softmax(x):
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
# 복원된 헤드를 저장할 리스트
restored_heads = []
for i in range(num_heads):
query = queries[i]
key = keys[i]
value = values[i]
# 내적 계산 후 스케일링
attention_scores = np.matmul(query, key) / scaling_factor
# 패딩 처리
mask = np.array([[token == 'PAD' for token in sentence] for sentence in sentences])
mask = mask[:, np.newaxis, :] # 차원을 맞추기 위해 확장
attention_scores = np.where(mask, -np.inf, attention_scores)
# 소프트맥스 적용
attention_weights = softmax(attention_scores)
# 밸류와의 곱셈
restored_head = np.matmul(attention_weights, value)
restored_heads.append(restored_head)
# 모든 헤드를 결합하여 원래 차원으로 복원
final_output = np.concatenate(restored_heads, axis=2)
# 어텐션 이후의 결과 중 특정 토큰들의 평균 값 계산
print("어텐션 이후의 결과 중 '커피', '한잔', '어때' 토큰의 평균 값:")
final_avg = np.mean(final_output[0, indices_of_interest, :], axis=1)
print(final_avg)